



A quick intro to Regular Expressions (RegEx)
- Tamas Wagner

- Jan 11, 2021
- 12 min read
Updated: Feb 13, 2025
Ever wondered how something as obscure and obfuscated as this ^[(]{0,1}[0-9]{1,4}[)]{0,1}[-\s./0-9]$ could be useful? This article is for you. |
Some people, when confronted with a problem, think
“I know, I'll use regular expressions.” Now they have two problems. - Jamie Zawinski, Netscape
In this brief article I want to get you familiar enough with regular expressions so that whenever you read or hear about them, you won't need to ask what the term means. It is by no means an exhaustive course, but I will link some of the most useful resources I've found at the end, so you can dive as deep as you need to.
// What is a Regular Expression?
Short answer: a RegEx is a string of characters which describes a search pattern. We can search for the described pattern in other strings, blocks of code, HTTP responses, Shakespeare sonnets, what have you.
Long story: Regular Expressions are expressions written in a language of their own, which allows for quite complex patterns to be defined. They are a combination of a pattern string and a set of flags, which define how the pattern should be interpreted. The patterns can range from simple wildcards to search for substrings within a text or validate a trivial format, all the way to complex expression containing extractable groups, ranges, references etc.
// RegEx Introduction: What is a Regular Expression good for?
Regular expressions are useful in a wide variety of situations, here's a list of their most common applications:
validating string formats: email addresses, phone numbers, passwords, credit card numbers, anything bound by a strict pattern
finding and replacing values in text to clean up, reformat, or change content
extracting parts from a body of text: values from an HTML/XML/JSON file, extensions/names of files, paragraphs from a novel, and so on
parsing various text files into values for import into a database, input for an API, etc.
// RegEx Fundamentals
Regular expressions have a lot of different flavors. For the purposes of this article, we'll be looking at JavaScript examples. As we've established, a RegEx is a pattern string and possibly some flags. In JS initializing a RegEx looks like this:
regExp = new RegExp("pattern", "flags"); - using constructor
regExp = /pattern/; - using a literal without flags
regExp = /pattern/gm; - using a literal with flags
Slashes / delimit a regular expression in JavaScript, much the same as ' or " delimit a string.
On when to use which, here's what MDN suggests - as you can see, the decision might impact performance, but not functionality.
Regular expression literals provide compilation of the regular expression when the script is loaded. When the regular expression will remain constant, use this for better performance.
Using the constructor function provides runtime compilation of the regular expression. Use the constructor function when you know the regular expression pattern will be changing, or you don't know the pattern and are getting it from another source, such as user input.
Source:
For the sake of example, let's take a simple RegEx, which searches for all the words 'dare' within a possibly multi-line string, defined as const regExp = /dare/gm; - we'll talk about the syntax later, just take my work for it for now.
Let's see how we can make use of a our newly defined Regular Expressions. JavaScript offers a handful operations to cover various scenarios:
RegExp methods
test - tests for a match in a string, true if the string matches, false otherwise
regExp.test("I dare you, I double dare you!") = true
Simple enough, as long as the pattern is found, it's true, false otherwise. In our example it's true since the string 'dare' does appear in the search string.
exec - executes the expression, searching for a match in a string - returns an array or null
regExp.exec("I dare you, I double dare you!") = ["dare", index: 2, input: "I dare you, I double dare you!", groups: undefined]
Exec returns an array, but it's values describe a single result each time, so if you want all the matches in a string, you need to keep calling the exec function until it returns null. This is usually accomplished with a while loop. Each result contains the matching substring, it's start index, the input string, and an array of groups. We'll see what that last one is a bit later.
String methods
Besides the methods from the RegExp prototype, there is a number of cases where you can use the expressions you define as parameters for functions.
match - searches for a match in a string - returns array or null
"I dare you, I double dare you!".match(regExp) = ['dare', 'dare'];
This is attacking the problem the other way around compared to exec, the string prototype has a function to find matches of a Regular Expression within the current string instance. The result is an array containing the matching substrings. There is also .matchAll, which returns an iterator instead of an array.
search - tests for a match in a string, returning the index of the match, or -1 if the search fails
"I dare you, I double dare you!".search(regExp) = 2;
This is the direct way of finding only the starting index of a match, in case you need it.
replace - search for a match in a string, and replaces the matched substring with a replacement substring
"I dare you, I double dare you!".replace(regExp, "curse") = "I curse you, I double curse you.";
Straight forward, you can use the RegEx to identify the substrings you want replaced with another value. This is one of the most frequently used applications of RegExes.
split - break a string into an array of substrings
"I dare you, I double dare you!".split(regExp) = [ 'I ', ' you, I double ', ' you!' ]
The resulting array has all the substrings before, between and after the matches, without the actual matching substrings. The entire string is returned if no matches are found.
// RegEx Syntax
Now that we saw the ways these patterns can be useful, it's time to take a look at the rules to follow when reading or writing them. First let's check out the possible flags:
g - Global search - all matches, essentially says the search shouldn't stop at the first matching result
i - Case-insensitive search - pretty self explanatory, ignore the case of the letters
m - Multi-line search - changes the meaning of ^ and $ from start/end of string, to start/end of line
s - Allows . to match newline characters
u - "unicode"; treat a pattern as a sequence of unicode code points
y - Perform a "sticky" search that matches only starting at the current position in the target string - it's set by populating the lastIndex property of the Regular Expression
// Regular Expressions Characters
Characters in a pattern can represent literal, meta, shorthand, non-printable characters. We refer to these as character classes. Let's check out what each class looks and works like when defining patterns.
Literal characters are like f , Q, 9 , # - they represent themselves
Metacharacters have special meanings, which - in most flavors - are the following: \ , ^ , $ , . , | , ? , * , + , ( , ) , [ , { .
\ - escape character - treat following metacharacter as literal (searching for . is done by using \. , \ is represented by \\ , etc.)
^ - start of a line (or string)
$ - end of a line (or string)
. - any character except a new line (the s flag can make it include the new line as well)
| - alternation - basically a boolean OR
? - optional operator (quantifier matching 0 or 1)
* - quantifier matching 0 or more times
+ - quantifier matching 1 or more times
() - character group - all characters from the set must match, in order
[] - character set - one character from the set must match, no ordering
{n} - the previous character or character group n times,
{n,m} - the previous character or character group at least n, at most m times

As always, Randall Munroe drew a relevant xkcd - https://xkcd.com/1638/
Shorthand character classes define convenient ways to target common groups of characters in a short and descriptive way.
\d, \w, \s - digit, 'word character' (a-Z0-9_), space
\D, \W, \S - NOT digit, word character, space
\b, \B - anchors for word boundaries
Non printable characters identify all sorts of characters which you can find in a string, but can't see in print or on screen. Some common ones are
\n - LF (line feed) character
\r - CR (carriage return) character
\t - tab
\R - any line break - LF, CR, LF and CR, vertical tab, unicode newline
\0 - null character
\xFF - hexadecimal, where F is [0-9A-F]
I'll list a couple of common examples and their description, so you can some of the above syntax applied. The examples are inspired from the awesome collection over at [Digital Fortress], but I did modify most of them a bit.
Examples:
/^[1-9]\d*$/ - whole number, so any number of digits not starting with a 0
We match the start of the line/string ^ , then any digit except 0 , followed by any digit at all, denoted by the \d, zero or more times, as quantified by the * , followed by the end of line/string $ . The metacharacters ^ and $ denote start and end of either the whole line or the pattern itself regardless of the line based on the m or multi-line flag.
/^[\w\s-]+\.[A-Za-z]{3}$/ - filename with a three character extension, alphanumeric, underscore, dash and spaces allowed in the name of unlimited length
Again, we begin with ^ , then any of the choices from a set of characters in between [ ] : \w (digit, letter, underscore), \s (whitespace), or dash - , repeated 1 or more times as quantified by the metacharacter + , followed by a single, actual . character, and then exactly 3 characters, as quantified by the {3} , which are either lower or uppercase letters [A-Za-z] , and finish with $ .
/<.+\s(\w+="\w+")>|</?[\w\s]*>/ - tags from HTML or XML content, both opening and closing, including attributes.
We have a top level boolean or, | , which tells us we should match either one of the two patterns, both contained between < and > characters. The first one starts off with any character at least once or more times, represented by .+ , and goes on to a group repeated zero or more times, having the form of 1 or more word characters \w+ followed by an = sign, and one or more word characters between " double quotes. This will match opening tags with any number of attributes. The second one matches both opening and closing tags due to the optional \? after the starting < character, and allows any word characters or whitespaces before the closing > . Between the two we get all opening tags with or without attributes along with any closing tag.
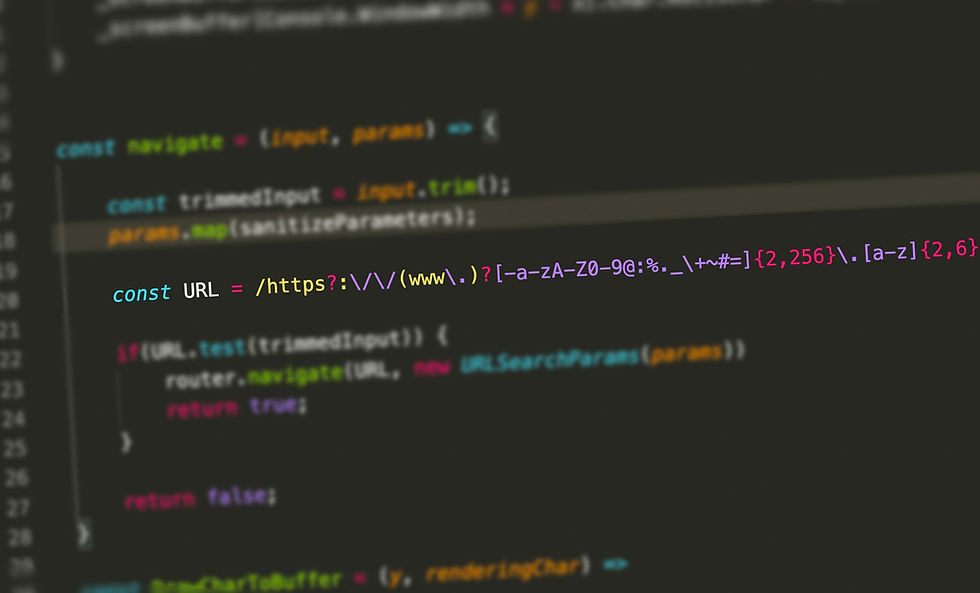
I'll leave a longer, more complex one for you to work your way through, it checks if a string is a valid URL.
/https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{2,256}\.[a-z]{2,6}\b([-a-zA-Z0-9@:%_\+.~#()?&//=]*)/ - work through this one to get a bit of confidence in interpreting RegEx. Pro tip, head over to RegEx101 and paste it into the RegEx field to get a description of each part does on mouse hover. Also, you can try it out in real time.
// Groups
( ) - can be used to create (capturing) groups, which means their value can be extracted after the match has been performed. Capturing groups can be referenced in the pattern.
\1 , \2 ... - can be used to reference the capturing groups
Example: (ha)\1 - this matches haha from hahaha ([a-z])_\1 - this matches a_a, but not a_b
A reference to a capturing group doesn't repeat the rule, but the exact match it captured. To get access to it's contents in JS, we can use
String.match(RegExp) or RegExp.exec(String)
Both return arrays, which contain also the groups that were found and captured. The first elements of the array (for each subsequent match) are the match itself, followed by the captured groups.
Example: /([M|m]rs*) (\w+) (\w+)/ applied to mr. James Hetfield returns ["mr. James Hetfield", "mr", "James", "hetfield"] 'Mr James Hetfield'.match(/[M|m]rs* (\w+) \w+/)[1] will result in "James", extracting the only capturing group (the first element would be the entire matching string).
(?: ) - this is a non-capturing group, backslash reference numbers are skipped.
A group matched multiple times keeps the last match in the result.
Example: 'acbd'.match(/(\w)+/) will return ["abcd", "d"]
(?<name> ) - Named capturing groups produce an object along with the array,
Example: /[M|m]rs* (?<firstname>\w+) \w+/ applied to mr. James Hetfield returns { 0: "mr. James Hetfield", 1: "James", groups: { firstname: "James" }, ... }
Lookaround (lookahead and lookbehind)
Lookarounds are a way to define a piece of a pattern by constraining it in reference to the previous or following piece. You can define a pattern to be or not be preceded or followed by something. Non-capturing groups and backslash reference numbers are skipped for all lookarounds.
Lookahead
(?= ) - positive lookahead (something followed by something else). The group itself is not included in the match, it's there to define what should follow the previous rule.
Example: ^John(?= [S|t]) will match the Johns in John Snow and John the Revelator, but not John Cena.
(?! ) - negative lookahead (something not followed by something else) The group itself is not included in the match, it's there to define what should not follow the previous rule.
Example: ^John(?! [S|t]) will match the John in John Cena.
Lookbehind
(?<= ) - positive lookbehind (something preceded by something else) The group itself is not included in the match, it's there to define what should follow the previous rule
Example: (?<=(\w+ ){2})Terrier matches the Terrier from the first line, but not the second two - so the word Terrier following two words.
Jack Russel Terrier
Pitbull Terrier
Scottish Terrier
(?<! ) - negative lookbehind (something not preceded by something else) The group itself is not included in the match, it's there to define what should not follow the previous rule
Example: (?<!(\w+ ){2})Terrier matches the two Terriers from the last two lines above, but not the first one, basically Terrier not following two words.
Lookaround expressions can contain any RegEx without additional lookarounds. Capturing groups work, and can be referenced outside as well.
// When NOT to use a RegEx
It's easy to get carried away, especially when you start getting a good grasp of how to write a regular expression, but remember, just because you have a new hammer, not everything is a nail.
Two of the most common arguments against using a RegEx are the following:
When there is a more easy to read solution
This usually applies when attempting to replicate built in or commonly used functions from languages or libraries. In short, it's always better to rely on
Example: myString === myString.toLowerCase() instead of /^[a-z]*$/.test(myString)
for two reasons. Firstly, odds are that a built in function is much more reliable, since it's continuously being tested by a huge mass of engineers while doing their day to day work. Secondly, even if you come up with a solution just as robust as a built in function or a simple new subroutine, it's not worth it unless it's going to be clearly readable and easy to maintain. Both of these attributes usually apply less and less as a RegEx grows longer and more complex.
2. When the regular expression is costly
Parsing, tokenization, for example - always use specialized tools for concrete tasks when they exist. Every RegEx should practically be trivial. This sounds similar to the above, but it's important to understand that regular expressions have a wide domain where they lend themselves well, and it's usually in places where you'll not have an obvious alternative.
// Assorted good-to-know tidbits
Always be careful when using nested quantifiers or alternations
They can result in catastrophic backtracking (unless everything is mutually exclusive)
Example: Let's say you try to match these strings xxxxxxxxxxy xxxxxxxxxx xxxxxxxxxxxxxxxxx with this pattern (x+x+)+y. The patten nests a variable number of x characters a variable number of times, which is horribly costly to evaluate.
If you try this regex on a 10x string in RegexBuddy's debugger, it'll take 2558 steps to figure out the final y is missing. For an 11x string, it needs 5118 steps. For 12, it takes 10238 steps. Clearly we have an exponential complexity of O(2^n) here. At 21x the debugger bows out at 2.8 million steps, diagnosing a bad case of catastrophic backtracking.
Source: https://www.regular-expressions.info/catastrophic.html
2. RegEx is greedy by default
Quantifiers in a RegEx will always try to match as much as possible, unless followed by ?, which in this case mark the group lazy - i.e. try to match as little as possible.
Example: Using these two patterns <span>.*<\/span> vs <span>.*?<\/span> on the following piece of HTML <span>This is the first span. We want only this.</span><span>Not this!</span> will return the entire piece or just the first span, depending on lazy/greedy evaluation.
3. Free spacing RegEx and comments
There is a flag, /x, which in some engines allows adding whitespace characters and line breaks inside some parts of regular expressions without changing their meaning. This is useful when you want to break out a RegEx to multiple lines, and comment each line. When free spacing is enabled, everything on a line after # is treated as a comment. Beware - \x doesn't work in ES6.
4. Using non-capturing groups when the group is not required should yield better performance
5. Using anchors whenever possible improves performance
\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3} runs much slower than ^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}
6. The more specific a RegEx, the more likely it's faster (rule of thumb: longer Regular Expressions are quicker)
7. When checking for matches that are one after another, without anything in between, /y (sticky) becomes handy
Example: [\d|+|-|=|\n]+$/gy will match the first two lines, but not the third from the lines below
1+1=2
3+2=3
2x+3=8
>>> Common pitfalls
* matches the null string, (whateverYouWant)* will match every line
forgetting ^ $ when trying to match a whole line
missing \ when looking for literals which are metacharacters in RegEx
I'd like to end on a piece of advice that I consider very important. Treat RegExes just like functions in your code, as first level citizens. They need iteration, testing, code review, documentation and maintenance. Keep that in mind anytime you decide to solve a problem using regular expressions, otherwise it can easily bring on both faulty logic and difficulty in maintenance.
// Resources
Online RegEx testers
Cheat sheets
RegexEgg - long, distinguishes between environments
Cheatography - concise and nicely laid out
Debuggex - FIlterable
Tutorials, Tips and Tricks
JavaScript specific pages
Fun articles
// Tamas Wagner // JAN 11 2021


